Notes
Here are a few short notes I have recently started making about tools and developer workflow. These notes may not be particularly readable to others, but provide a narrative of my progress as a developer.
-
Gits DAG of DAGs
April 20, 2025
Git is ubiquitous, but how does it so efficiently track changes? Inspired by a recent presentation I gave on Git internals and as background for my personal ‘project lit,’ I wanted to share a simple way I visualize Git’s internal structure. This mental model can be incredibly helpful for troubleshooting and truly understanding how Git works, particularly its ‘DAG of DAGs’ architecture.
The commit history is a Directed Acyclic Graph. This can be seen by typing the pretty
git log –oneline –graph –all –decoratecommand (I remember the flags by the acronym A DOG).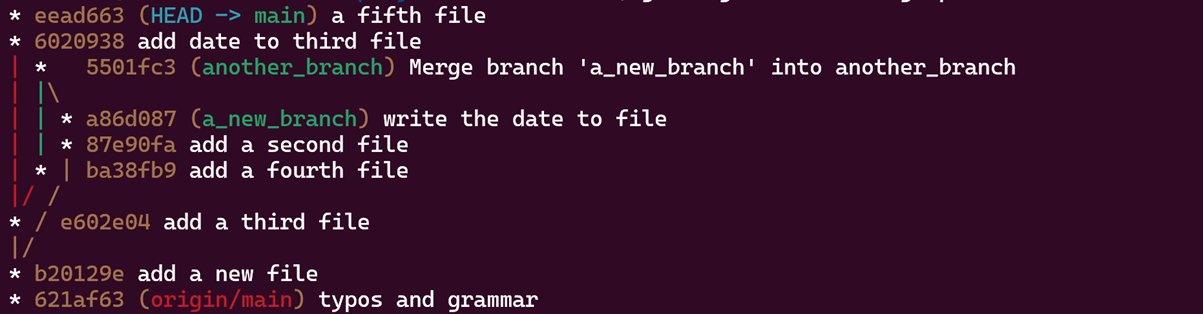
The “inner” DAG comes from how git represents each commit. A commit doesn’t store the files changed directly but instead contains a pointer i.e. a hash of a tree object of the root directory of the repository. The commit also stores other information about the commit – date, author and commit message. The tree object is git’s representation of a single directory’s contents at the specific commit.
The tree object is essentially a list of entries with each entry containing
- A mode indicating if it’s a file, executable, sym link or sub directory
- An object type (blob or tree)
- A hash of the blob or tree object it points to
- The name of the file or subdirectory
It’s this structure of tree objects potentially pointing to other tree objects (for subdirectories) that forms the ‘inner DAG.’ Because a directory cannot contain itself or an ancestor, this file system representation within each commit is inherently acyclic, mirroring the actual file structure of your repository at that point in time.
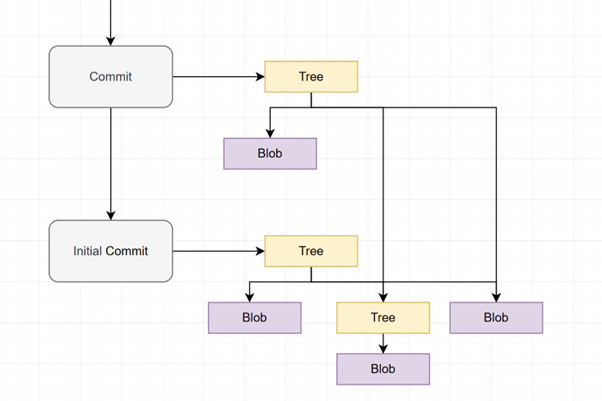
In this image, the second commit only changes a single file from the initial commit. The tree object will hence point to the tree and blob object from the initial commit which haven’t changed. In this image, consider that the second commit reflects a change to only a single file from the initial commit. As a result, the new root tree object of the second commit will still point to the unchanged tree and blob objects from the initial commit with only a single new blob for the modified file.
Content-Addressable Storage
A cornerstone of Git’s efficiency lies in its use of content-addressable storage, primarily for blob objects. Each file’s content is hashed, and this hash becomes its identifier. If the same file content appears in multiple commits or different parts of the repository, Git stores the blob only once. Different tree objects will simply contain pointers (the hash) to that single, shared blob. The same principle applies to tree objects: if a directory’s contents (and thus its tree object’s structure and pointers) haven’t changed between commits, the new commit can simply point to the existing tree object’s hash. This massive reuse of unchanged objects, facilitated by hashing, is what dramatically reduces the storage footprint of a Git repository, alongside techniques like packfiles.
Tracking structure
This nested graph structure comes with several advantages to git:
- Storage efficiency – unchanged files and directories aren’t duplicated
- Integrity – ensures data hasn’t been corrupted
- Calculate differences rapidly – comparing two versions of a directory just involves comparing the hashes of the tree objects.
- Lightweight branches – pointers to commits
Conclusion
This internal “DAG of DAGs” architecture, built on simple hashed objects, allows for features we take for granted like lightweight branching, fast diffing, data integrity and managing the size of complex project histories. For more on how this works see the official documentation or my notes on the git demo I gave.
-
Git Presentation Demo
March 27, 2025
Tomorrow I will give a presentation to colleagues titled “Git Internal”. This will cover a simple overview of how git tracks changes and how they are represented and stored efficiently. This presentation, compared to my previous ones, will focus more on a demo at the CLI where I run a series of commands stepping through git objects (trees, commits, blobs and tags) and references. I also cover the HEAD pointer and how you would recover from a deleted branch and log, as well as a quiz on useful git commands. The demo is based on the walkthrough in Chapter 10 of the git docs with some edits and changes. For reference, these are the commands I plan to use in the demo (with the git hashes changed).
The .git folder slide (from xr repo) cd .git ls -l ls objects ls objects/00 ls objects/01 -
Project LIT
March 23, 2025
I am starting a new personal project to rewrite Git! Check out the initial discussion on the new “Project Lit” page.
-
Developer Goals
March 14, 2025
There are a few goals that help guide me in becoming a better developer. Keeping these at the core of what I do will help me focus on what is important in the growth of my skills:
- Take time to configure your workflow.
- Discuss review comments, determining the reasons for suggestions.
- Learn new tools, prioritising understanding for long term benefits.
- Work on code in a variety of contexts at differing layers of abstraction.
-
Using Vim
March 10, 2025
Vim is an investment, where you must endure the initial ‘hump’. Having started the easy way with the VS Code extension a couple of weeks ago I now think I am about back to the same speed as before without it. To make it easier, I have stuck with just the basic operations to learn them faster and not get overwhelmed. To make the transition easier, I found it paramount to allow Ctrl C and Ctrl V to work in VS Code, otherwise there would be awkward issues of wanting to paste or copy to other sources.
Currently, I am considering the best shortcut to use for navigating between panes on VS Code - I am not much of a fan of Ctrl w then h or l. Then next commands that I am learning to use are capital W and B as well as navigating using shift and square brackets. Either way I have enjoyed learning vim so far and would recommend it to others.
-
Terminal Convergence, the old website
March 09, 2025
Terminal Convergence was the name given to my previous website. I am not really sure why I chose this name, but it stuck, and I bought the accompanying URL. More recently, I have wanted to update this website, making it closer to a personal blog and give it a redesign. However, the old website still serves a somewhat meaningful purpose (despite my doubts about the number of users). On the terminal convergence website, there are machine learning predictions for future river level predictions. In fact, the forecast gives a 10-day prediction, more than any other existing forecasts.
I am partly amazed that it does still run. The code is quite a jumble and there are many dependencies on many public APIs for its inference data each day. Therefore, I decided to keep it running to showcase previous projects.
What was terminal convergence is now found at tc.leoellis.uk. This was easily set up by adding a CNAME record pointing the subdomain to the base domain
tc.leoellis.uk -> leoellis.ukand adding some config to theapache2server. This allows the two websites to reside in different locations within the file-system. -
Deploying to the Raspberry Pi
February 24, 2025
An easy method for deploying the website to the Raspberry Pi is using Git. This approach provides the added benefits of rollback, version control, and backup. The following script automates the Jekyll build process and handles Git push/pull operations, ensuring the latest website changes are deployed to the Raspberry Pi:
# A script to deloy to the Raspberry Pi jekyll build cd _site git add --all git commit -m "Web deploy `date`" git push ssh pi@leoellis.uk "cd html; git pull"I wonder if there are more efficient ways to handle this deployment. Perhaps deploying directly to the remote host instead of relying on Git.
-
Tmux Config
February 23, 2025
My current tmux setup. This has a long way to go but it is good to get something here if I ever need to set tmux up again.
# Allow scrolling with the mouse wheel set -g mouse on # Allows for faster key repetition set -s escape-time 0 # Highlight active window set -g window-status-current-style bg=red,fg=white,bold # Faster command sequences set -s escape-time 0 # Change to bind seq to Alt-f set-option -g prefix M-f # Change navigation between tables bind-key k next-window bind-key j previous-window # Make sure there is colour in the terminal set-option -g default-terminal "tmux-256color" set-option -sa terminal-overrides ",xterm-256color:RGB"