Gits DAG of DAGs
Git is ubiquitous, but how does it so efficiently track changes? Inspired by a recent presentation I gave on Git internals and as background for my personal ‘project lit,’ I wanted to share a simple way I visualize Git’s internal structure. This mental model can be incredibly helpful for troubleshooting and truly understanding how Git works, particularly its ‘DAG of DAGs’ architecture.
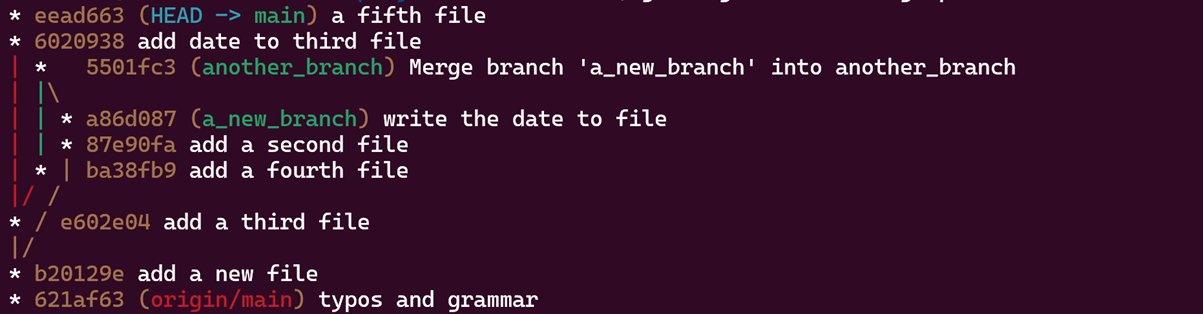
The commit history is a Directed Acyclic Graph. This can be seen by typing the pretty git log –oneline –graph –all –decorate command (I remember the flags by the acronym A DOG).
The “inner” DAG comes from how git represents each commit. A commit doesn’t store the files changed directly but instead contains a pointer i.e. a hash of a tree object of the root directory of the repository. The commit also stores other information about the commit – date, author and commit message. The tree object is git’s representation of a single directory’s contents at the specific commit.
The tree object is essentially a list of entries with each entry containing
- A mode indicating if it’s a file, executable, sym link or sub directory
- An object type (blob or tree)
- A hash of the blob or tree object it points to
- The name of the file or subdirectory
It’s this structure of tree objects potentially pointing to other tree objects (for subdirectories) that forms the ‘inner DAG.’ Because a directory cannot contain itself or an ancestor, this file system representation within each commit is inherently acyclic, mirroring the actual file structure of your repository at that point in time.
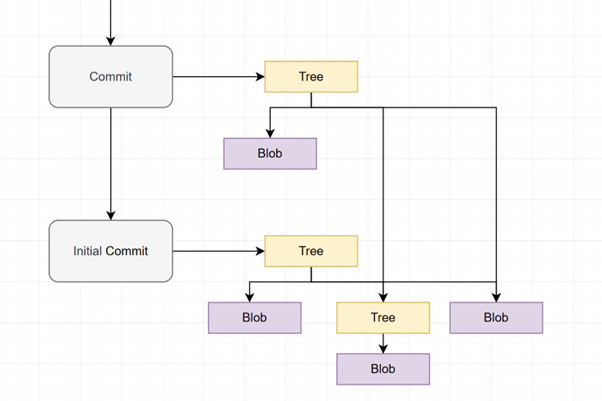
In this image, the second commit only changes a single file from the initial commit. The tree object will hence point to the tree and blob object from the initial commit which haven’t changed. In this image, consider that the second commit reflects a change to only a single file from the initial commit. As a result, the new root tree object of the second commit will still point to the unchanged tree and blob objects from the initial commit with only a single new blob for the modified file.
Content-Addressable Storage
A cornerstone of Git’s efficiency lies in its use of content-addressable storage, primarily for blob objects. Each file’s content is hashed, and this hash becomes its identifier. If the same file content appears in multiple commits or different parts of the repository, Git stores the blob only once. Different tree objects will simply contain pointers (the hash) to that single, shared blob. The same principle applies to tree objects: if a directory’s contents (and thus its tree object’s structure and pointers) haven’t changed between commits, the new commit can simply point to the existing tree object’s hash. This massive reuse of unchanged objects, facilitated by hashing, is what dramatically reduces the storage footprint of a Git repository, alongside techniques like packfiles.
Tracking structure
This nested graph structure comes with several advantages to git:
- Storage efficiency – unchanged files and directories aren’t duplicated
- Integrity – ensures data hasn’t been corrupted
- Calculate differences rapidly – comparing two versions of a directory just involves comparing the hashes of the tree objects.
- Lightweight branches – pointers to commits
Conclusion
This internal “DAG of DAGs” architecture, built on simple hashed objects, allows for features we take for granted like lightweight branching, fast diffing, data integrity and managing the size of complex project histories. For more on how this works see the official documentation or my notes on the git demo I gave.